浅谈第一次数模比赛的体验
上个星期和几个朋友一起打了第三届长三角数学建模比赛,作为第一次打数模的小白来说感觉就是,有大佬带好爽😍。
这次比赛我们选择的是B题,题目描述如下:
题目描述
看完题目描述,很容易看的出来这是一道大数据题目,需要预测和对参数做一下重要性评估。在整个论文中,我负责的是第二问重要性评估和对论文的排版($\LaTeX$)。
数据收集
作为一道大数据题目,主办方并没有给数据,要我们自己找。这也是整个比赛最难受的地方,我们第一去找的数据是新能源汽车的产量和销量,通过google我们成功找到来一些资源,包括收费的和不收费的😢。在这些资源中,我们又找到了数据的来源,国家统计局,和各地的经济发展公报,比如2020年江苏省国民经济和社会发展统计公报,在这里可以找到如下数据
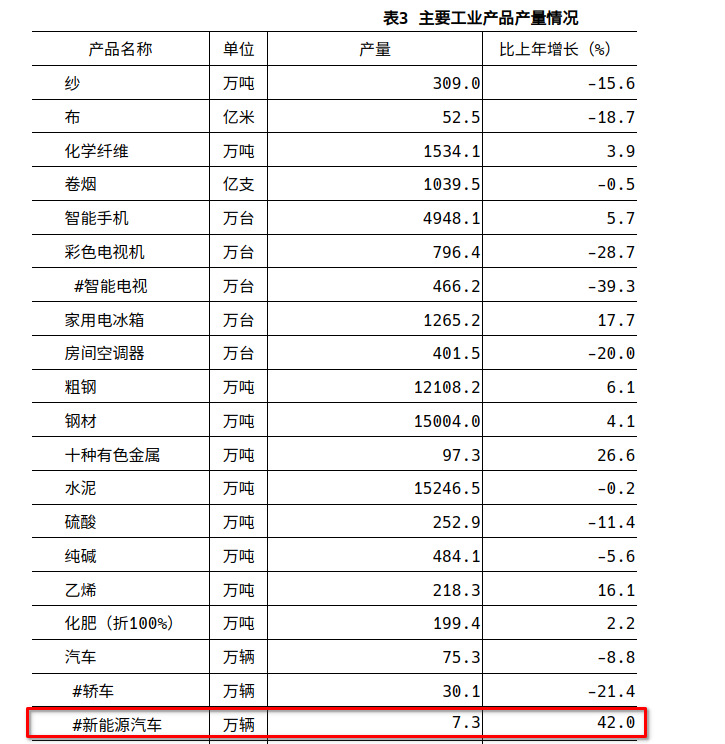
这里对新能源汽车的产量有特别标注出来,其他省份也一样但也有比较奇怪的,比如上海市2018年公报内容是这样的
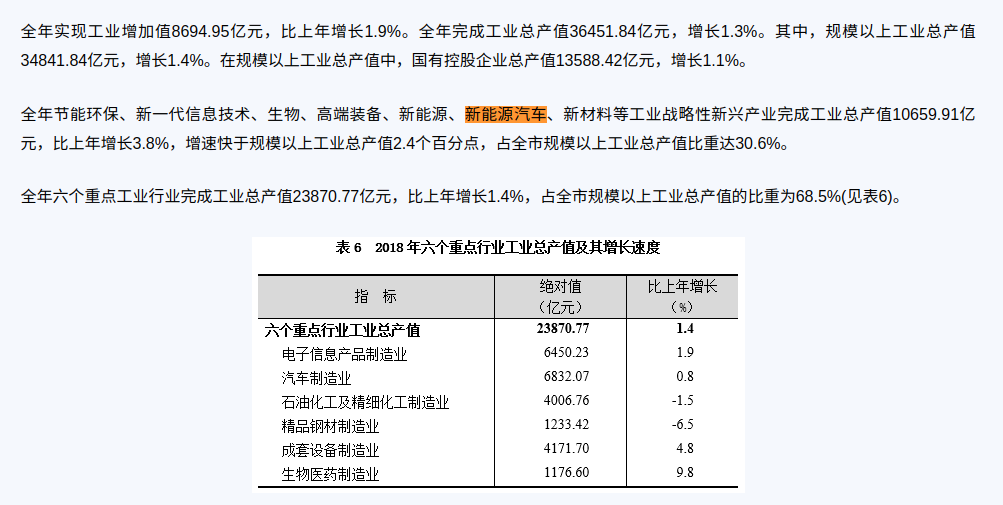
并没有把新能源汽车的产量特别标注出来,而是与其他新兴产业合在一起给来一个增长百分比。那我们去找2017年的
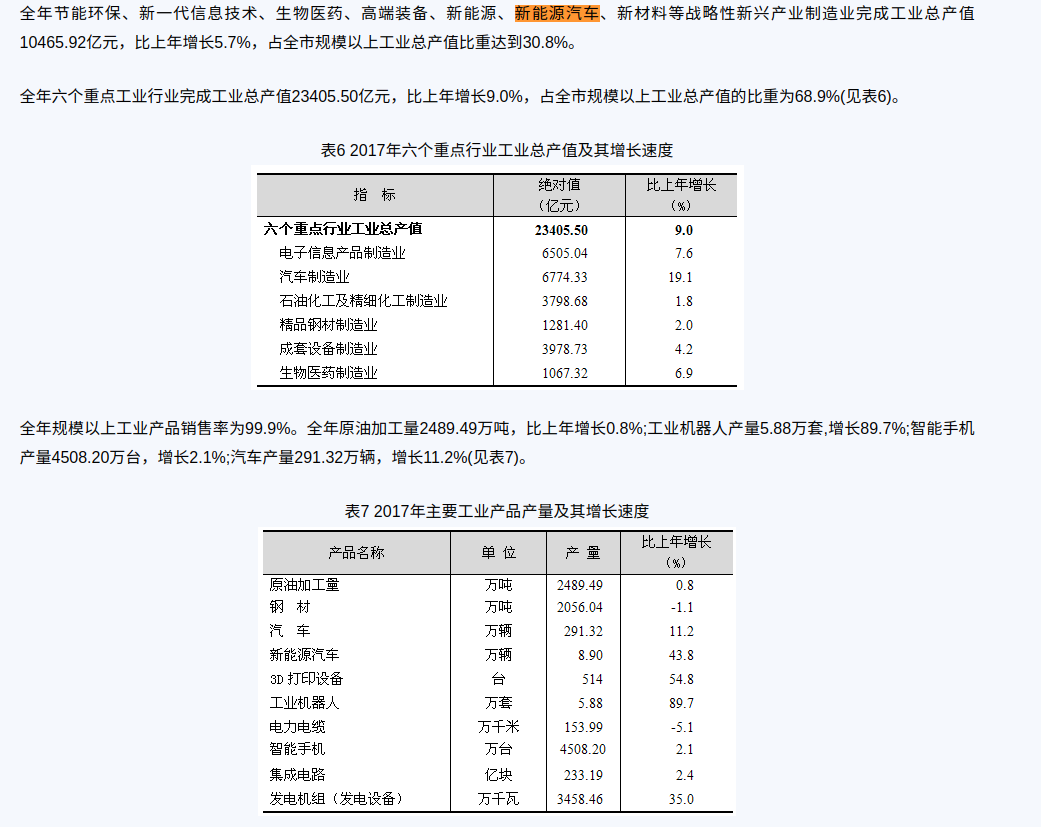
跟2018一样,2016同样如此。只有2019年开始才跟江苏省一样把新能源汽车标出来,但是江苏,浙江,安徽都是从2016年开始就这样了。还有就是2016年前的官方一点数据都咩有,呜呜~。2016-2022就七年的的时间,而且还是以年为单位的,也是就我们要用7个数据去预测后面3各数据,对于机器学习或者神经网络来说我感觉还是比较难的。
在找数据的过程中,我认为最离谱的还是那些卖数据的。明明他们的数据也基本是从官方渠道来的,而且这些数据都是公开的,非公开的国家数据应该也不能拿来卖吧(?。还有一些是专门卖这个赛题的数据的,更离谱了,甚至有些数据还是错的,大无语。
重要性评估
由于最近有学习人工智能方面的东西,尤其是深度学习,所以一下子就想到了随机森林算法。在得到数据之后,利用sklearn很容易构建出一个模型。我们收集到的的有关数据包括
- 年份
- 燃油价格
- 电动车充电成本
- 电动车平均价格
- 燃油车平均价格
- 新能源汽车能源效率
- 燃油车能源效率
- 新能源车政府补贴金额
- 新能源汽车企业数量
- 新能源汽车专利申请数量
- 新能源汽车充电桩数量
- 新能源汽车燃油车保有量比
并且使用新能源汽车燃油车保有量比作为新能源汽车和燃油车的竞争量。
from sklearn.ensemble import RandomForestRegressor
rfc = RandomForestRegressor(n_estimators=82,random_state=4, n_jobs=1)
rfc.fit(x_train,y_train)
y_pred = rfc.predict(x_test)
y_train_pred = rfc.predict(x_train)
#特征重要程度分析
feat_labels = x_train.columns[0:]
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
print('特征重要程度排名')
for f,j in zip(range(x_train.shape[1]),indices):
print(f + 1, feat_labels[j], importances[j])
#预测准确度
plt.plot(np.arange(10), np.concatenate((np.array(y_train)[:, 0],np.array(y_test)[:, 0]), 0), "go-", label=u"True Value")
plt.plot(np.arange(10), np.concatenate((y_train_pred,y_pred[:])), "ro-", label=u"Pred Value")
plt.legend()
plt.show
代码并不是完整的,只是对构建模型的过程做一个说明。
最后得到的结果是
模型准确率
0.9787107598213716
特征重要程度排名
1 电动车平均价格 0.1772720080231971
2 新能源汽车企业数量 0.1591644602871651
3 燃油车平均价格 0.15346266562334077
4 新能源汽车专利申请数量 0.11298818816848044
5 新能源汽车充电桩数量 0.09784914547467999
6 新能源车政府补贴金额 0.09755242493785697
7 新能源汽车能源效率 0.07244326299206993
8 电动车充电成本 0.06197578291279916
9 燃油车能源效率 0.0349670282637589
10 燃油价格 0.03232503331665166
以及预测值和真实值的差图
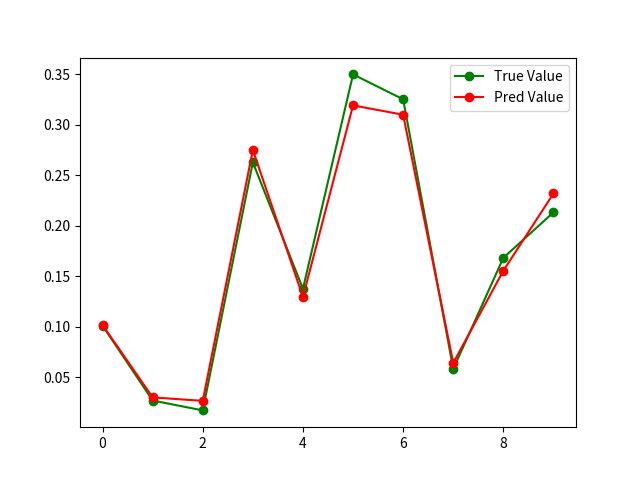
看到这个图还是感觉数据实在太少了。xd
论文排版
论文排版我们使用的是$\LaTeX$,先说说LaTeX对于我来说主要的用途吧。其实就是用来写写blog,因为blog中关于数学公式的东西比较多,而hexo中基本是使用LaTeX来进行公式的编写,所以在此之前我只对LaTeX的公式比较熟悉,从来没有用于排版。
首先是配置LaTeX的环境,说实话我到现在也没有配好LaTeX+VSCode的环境,所以现在我还是使用Kate加命令行编译的方式来输出PDF。非常的丑陋和繁琐。
其次是LaTeX本身。由于之前我在本地编译SageMath的时候已经安装过了texlive(我电脑上的系统是OpenSuSE),我以为这样就够了。于是在看了一些LaTeX的教程之后开开心心的去写了一些例子,结果报了类似这样的错误
not found ctex.sty
我也忘了是sty还是什么文件了,反正就是缺少了这个宏包。后来知道这个宏是用来显示中文的。然后呢想着去手动安装一下这个东西,结果搞了很久都没好。实在把我搞烦了,然后转战Typst,这就不得不说Typst的强大了,可以从github上下载Typst的可执行文件,发现压缩包里东西很少。虽然说Typst刚刚起步,到后面可能第三方插件包也会多起来,但是单单一个Typst已经足够强大了。
本来Typst用的也挺好,但是用着用着遇到问题了,然后去网上找解决方案,发现网上关于Typst的教程好少。那怎么办,问题解决不了啊,又只能转回LaTeX。然后发现LaTeX,有官方的软件包集成了很多宏包
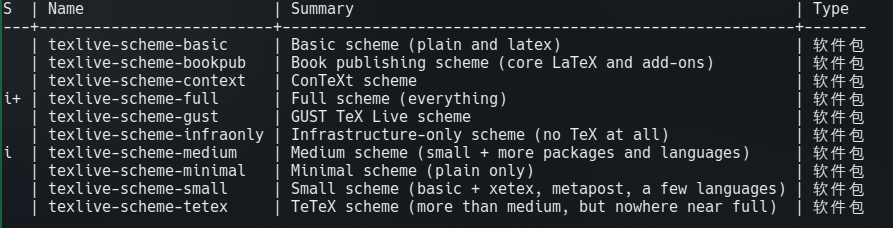
先前编译SageMath安装的是medium那个,然后我就试着装了full的那个软件包。艹又是2个G,4000多个包。其中就包含了ctex。
之后就开开心心地使用LaTeX来进行论文的排版了,最后写出来的tex源码文件有将近800行。
最后吐槽一下LaTeX的编译
编译到后面出现的文件也太多了吧,个人感觉只有paper.log看的比较多。
论文结果
这里就放一下我负责的随机森林回归算法的部分吧
{% pdf https://cdn.jsdelivr.net/gh/clingm/PicGo-image/demo.pdf 600px %}