instro #
K均值聚类(K-Means clustering)是一种常见的无监督学习算法,用于将数据集划分为K个簇。
算法伪代码如下

使用西瓜数据集4.0来对算法进行测试
main idea #
- 距离算法使用欧几里得距离,与sklearn和matlab一致
- 使用最大迭代次数和质心偏移量来控制算法迭代过程
- 使用簇内距离的平均值作为模型评估的标准
implement #
def kmeans(k, X, max_iter=100):
if isinstance(X, pd.DataFrame):
X = X.to_numpy()
# init vec
centroids = X[np.random.choice(len(X), k, replace=False)]
for _ in range(max_iter):
# calc distance
distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=2)
labels = np.argmin(distances, axis=1)
# new center
new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(k)])
if np.linalg.norm(new_centroids - centroids) < 1e-4:
break
centroids = new_centroids
return labels, centroids, distances
簇内平方和
def metric(X, labels, centroids, k=None):
if isinstance(X, pd.DataFrame):
X = X.to_numpy()
if k == None:
k = centroids.shape[0]
distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=2)
squared_distances = np.square(distances)
inertia = 0
for i in range(k):
inertia += np.sum(squared_distances[labels == i, i])
return inertia
test #
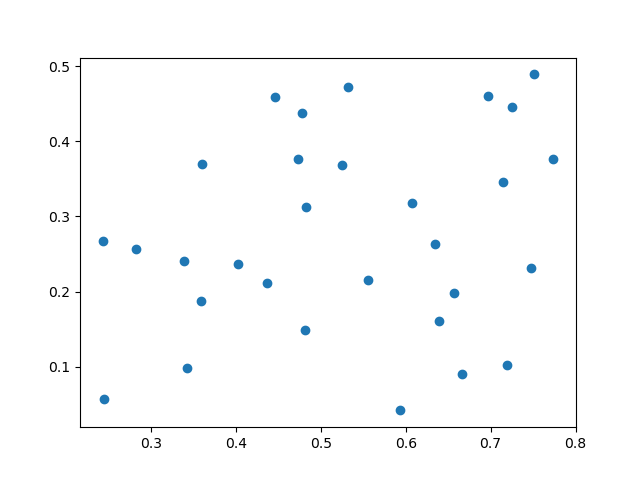
原始数据分布
聚类结果
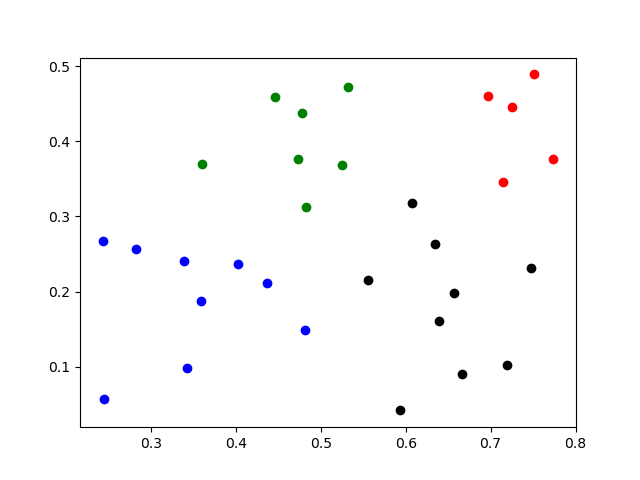
质心:
[[0.64666667 0.18044444]
[0.471 0.39928571]
[0.348 0.18955556]
[0.7322 0.4232 ]]
簇内平方和: 0.24863747301587302